SELFGOAL
👋 Hi, there! This is the project page for our paper: “SELFGOAL: Your Language Agents Already Know How to Achieve High-level Goals”.

SELFGOAL Code
Code for running SELFGOAL and experiments.

SELFGOAL Paper
Everything you need to know about our work.
Abstract
Language agents powered by large language models (LLMs) are increasingly valuable as decision-making tools in domains such as gaming and programming. However, these agents often face challenges in achieving high-level goals without detailed instructions and in adapting to environments where feedback is delayed. In this paper, we present SELFGOAL, a novel automatic approach designed to enhance agents' capabilities to achieve high-level goals with limited human prior and environmental feedback. The core concept of SELFGOAL involves adaptively breaking down a high-level goal into a tree structure of more practical subgoals during the interaction with environments while identifying the most useful subgoals and progressively updating this structure. Experimental results demonstrate that SELFGOAL significantly enhances the performance of language agents across various tasks, including competitive, cooperative, and deferred feedback environments.
SELFGOAL
Overview of SELFGOAL
Our paper, SELFGOAL: Your Language Agents Already Know How to Achieve High-level Goals aim to combine modular goal decomposition with learning from environmental feedback. SELFGOAL is a non-parametric learning algorithm for language agents, i.e., without parameter update. Concretely, SELFGOAL is featured with two key modules, Decomposition and Search which construct and utilize a subgoal tree respectively, namely GoalTree, to interact with the environment. Setting the high-level goal of the task as the root node in GoalTree, Search Module finds the nodes that are helpful for the status quo, and Decomposition Module decomposes the node into subgoals as leaf nodes if it is not clear enough.
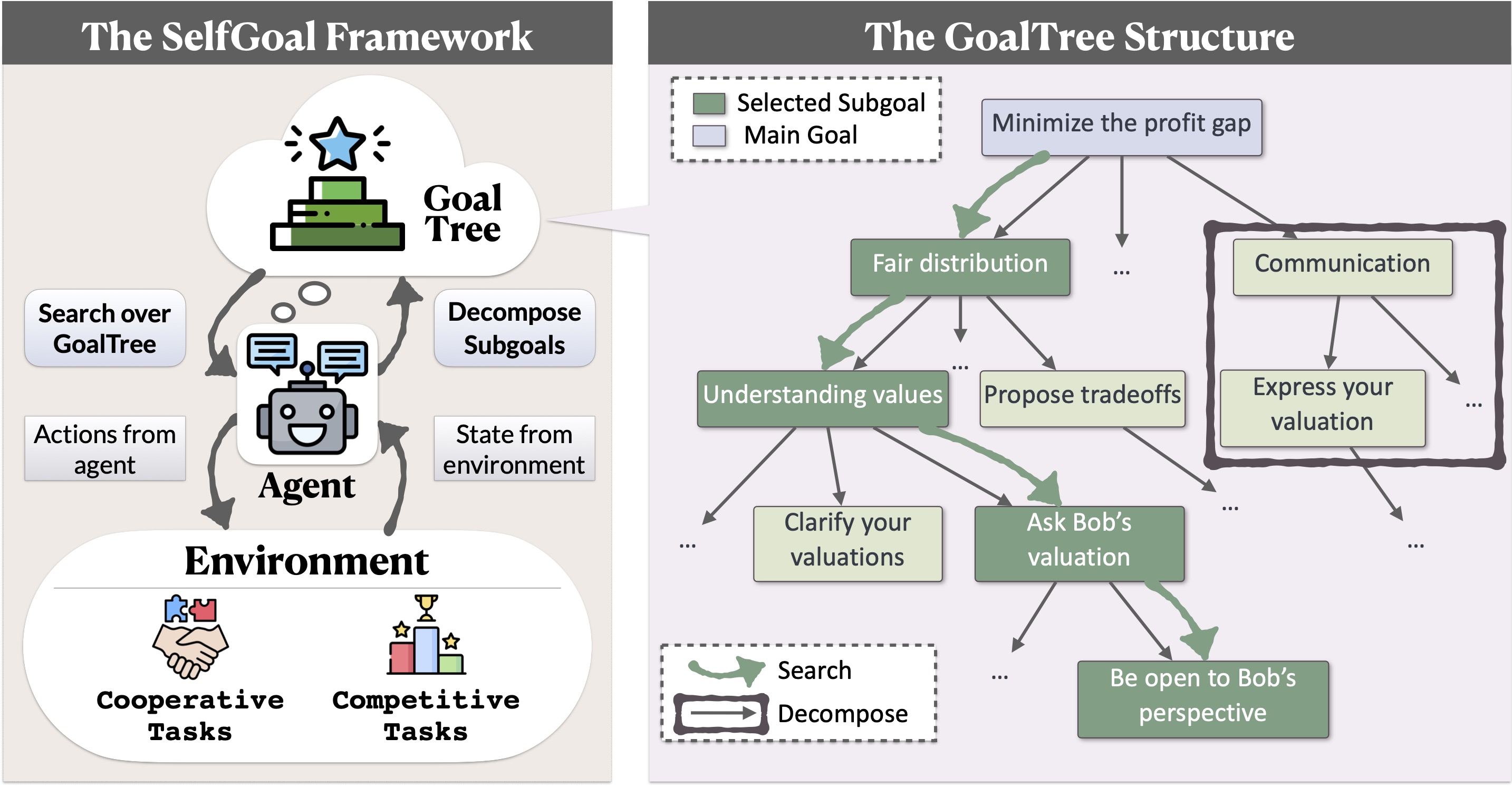
Details in SELFGOAL
1) Search Module: Identify the most suitable subgoals for the current situation, such as choosing the most useful subgoals to achieve the main goal. We use a representation of the current state as a description of the interaction history with the environment and consider the leaf nodes of each branch as potential subgoals. The LLM then selects the most appropriate subgoals, which leads to the updating of the instruction prompt for the next steps.
2) Decompose Module: Refine the strategy tree based on the current action-state scenario if it lacks specificity for guiding the agent effectively. The LLM deconstructs the selected subgoal and proposes new subgoals. A filtering mechanism ensures the uniqueness of subgoals by checking the similarity between them. If no new subgoals are added after several attempts, updates to the strategy tree are halted.
3) Act Module: After identifying useful subgoals from the strategy tree, the agent updates its instructions and interacts with the environment, using the derived subgoals to guide its actions.
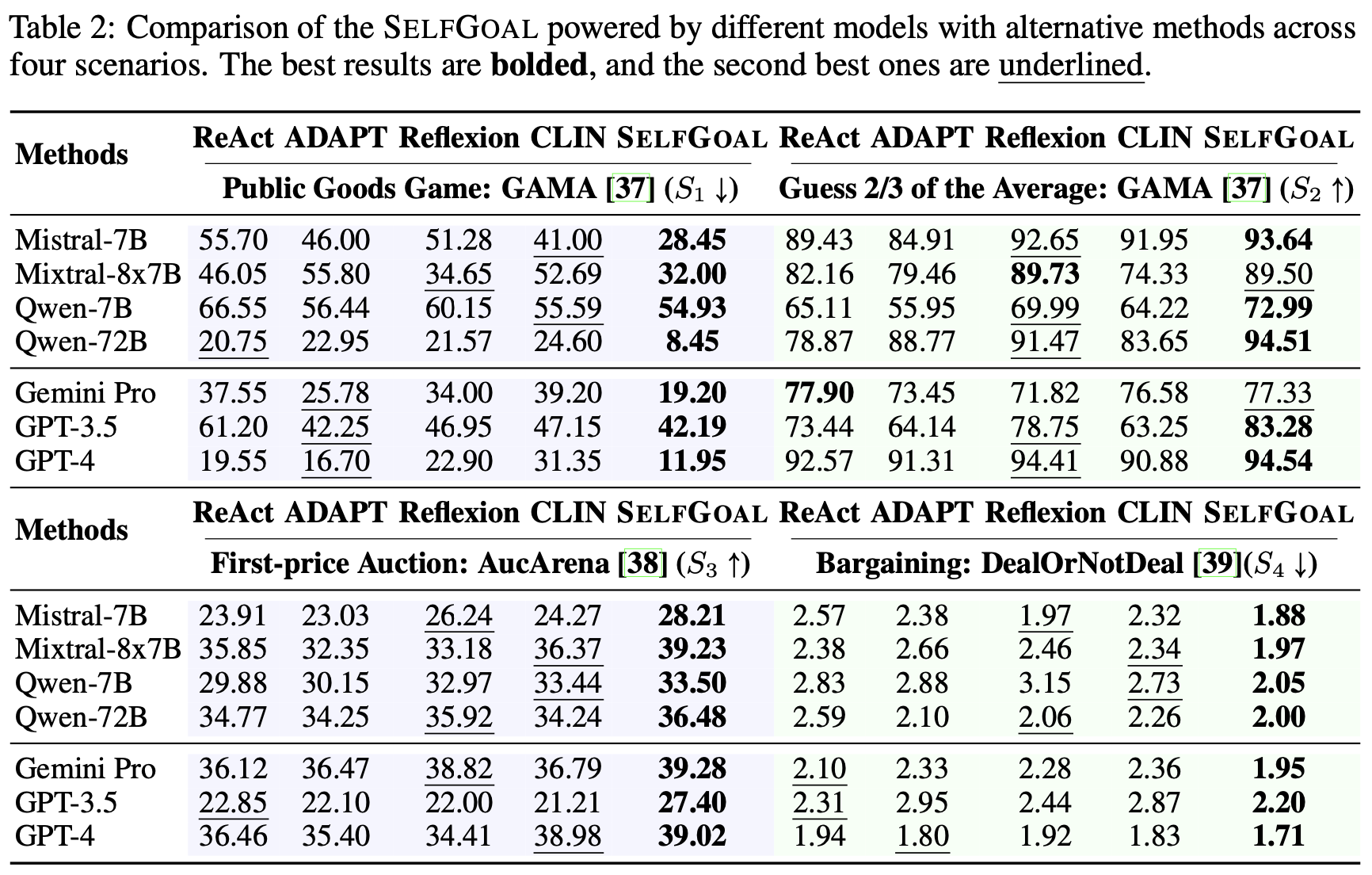
SELFGOAL outperforms all baseline frameworks in various environments
We evaluate SELFGOAL across 4 dynamic tasks with high-level goals, including Public Goods Game, Guess 2/3 of the Average, First-price Auction and Bargaining. Overall, our SELFGOAL significantly outperforms all baseline frameworks in various environments containing high-level goals, where larger LLMs produce higher gains.
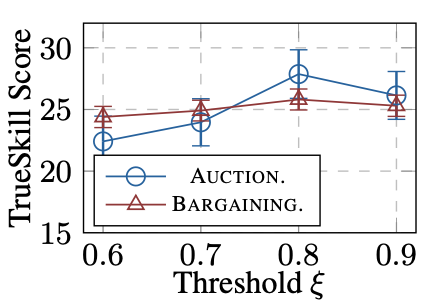
How does the granularity of guidelines in SELFGOAL affect task solving?
Here, we examine SELFGOAL' s performance adjustment through varying subgoal granularity by altering the threshold $\xi$. While deeper trees initially enhance performance, excessive detail eventually reduces effectiveness, as redundant nodes complicate the search module's task of selecting valuable guidance, often overlooking beneficial nodes. This underscores the need for a balanced depth in guidance trees to optimize agent performance without the pitfalls of over-detailing.
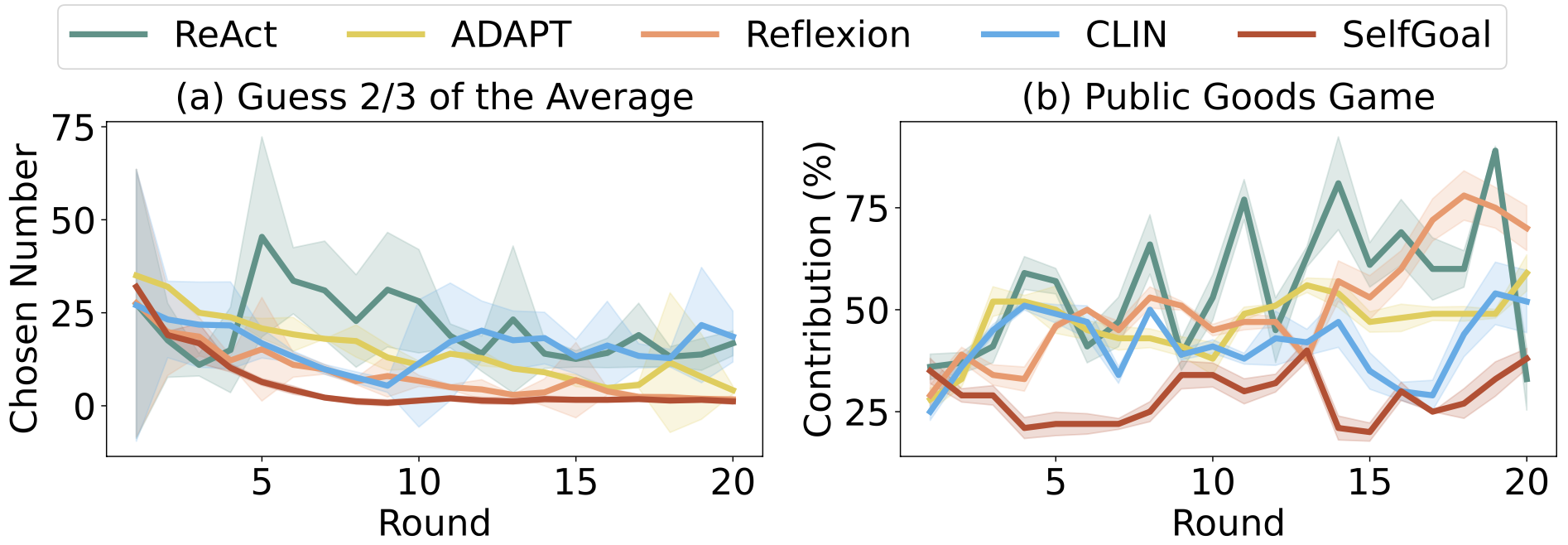
Can SELFGOAL improve the rationality in agents' behaviors?
With SELFGOAL, agents in the Public Goods scenario consistently act more rationally compared to those using alternative methods. For the Guessing Game, enhanced models showed smoother, more steadily declining curves, indicating quicker convergence to the Nash equilibrium.
Case Study
SELFGOAL provides agents with actionable guidance such as Ask clarifying questions, prompting agents to pay early attention to their opponent's psychological assessment and different valuations of items. After acquiring a partner's valuation, SELFGOAL then gives guidance such as make concessions, leading the agent to propose a plan that gives up a particular item in exchange for minimizing the profit difference.
In contrast, CLINE advises agents to consider the preference of the partner, which leads agents to focus on the opponent's preferences but may result in plans that sacrifice their own interests to improve the other party's income. ADAPT, which decomposes tasks beforehand, provides very broad advice such as equal allocation. This generic advice aims to minimize the profit gap but may not be suitable for scenarios lacking knowledge of the partner's valuation.

In conclusion, we demonstrate that SELFGOAL significantly improves agent performance by dynamically generating and refining a hierarchical GoalTree of contextual subgoals based on interactions with the environments. Experiments show that this method is effective in both competitive and cooperative scenarios, outperforming baseline approaches. Moreover, GoalTree can be continually updated as agents with SELFGOAL further engage with the environments, enabling them to navigate complex environments with greater precision and adaptability.
Authors
Ruihan Yang
Jiangjie Chen
Yikai Zhang
Siyu Yuan
Aili Chen
Kyle Richardson
Yanghua Xiao
Deqing Yang
Acknowledgements
Fudan University
Allen Institute for AI
Citation
@article{yang2024SELFGOAL,
title={SELFGOAL: Your Language Agents Already Know How to Achieve High-level Goals},
author={Yang, Ruihan and Chen, Jiangjie and Zhang, Yikai and Yuan, Siyu and Chen, Aili and Richardson, Kyle and Xiao, Yanghua and Yang, Deqing},
journal={arXiv preprint arXiv:},
year={2024}
}